Come potenziare la tua supply chain con l'aggregazione di dati
- Cosa sono i big data della supply chain?
- Quali sono le fonti dei dati della supply chain?
- Come ricavare valore dai dati della supply chain?
- Aggregazione, integrazione e interoperabilità dei dati
- Tecnologie che abilitano l'automazione e l'analisi dei dati
- Quali sono i reali vantaggi dell'analisi dei dati della supply chain?
- 4 modi per creare valore dai big data della supply chain
- Conclusioni
- Note
Indice contenuti

Viviamo in un mondo guidato dai dati. Nell'ultimo decennio, i dati sono diventati sinonimo di valore e la risorsa più preziosa al mondo. Quando si tratta di prendere decisioni per la nostra azienda, dobbiamo affidarci ai dati. È impossibile per le organizzazioni prendere decisioni accurate senza usare i dati.
"Per prendere decisioni accurate c’è bisogno dei dati."
I dati sono definiti come la parte più piccola ma più importante del processo decisionale, perché senza di essi non si può avere una base di ragionamento o di discussione¹. Già questa ampia definizione ci dà un'idea del perché siano così cruciale per le supply chain. Non è un segreto che oggi, in tutte le fasi della supply chain, vengono prodotte enormi quantità di dati ogni ora². Non si tratta di una semplice esagerazione. È questo infatti il motivo per cui quando si parla di supply chain si parla di "big data". Raccogliendo, analizzando, armonizzando e interpretando questi dati, un'azienda può creare soluzioni basate sui dati e migliorare l'efficienza operativa, i prodotti e i servizi.
Cosa sono i big data della supply chain?
I big data si riferiscono a insiemi di dati troppo grandi o complessi per essere gestiti con i metodi tradizionali di elaborazione. Sono associati a tre concetti chiave: volume, varietà e velocità. Il termine è stato utilizzato fin dai primi anni Novanta. All'inizio degli anni 2000, grazie alle straordinarie opportunità di raccolta e analisi dei dati offerte da Internet, il termine è diventato sempre più popolare e si è diffuso in diversi settori.
Non è difficile comprendere la sua penetrazione nel contesto della supply chain. In tutte le fasi della supply chain, dalla pianificazione alla consegna finale, viene prodotta continuamente una grande quantità di dati (volume). Oltre ai volumi elevati, questi dati sono generati in formati eterogenei (varietà) e crescono rapidamente (velocità).
Pertanto, non è sbagliato affermare che ogni supply chain genera big data. Senza dubbio, è questo il motore delle supply chain di oggi. I big data stanno fornendo alle supply chain maggiore accuratezza, chiarezza e comprensione dei dati e portano a una più ampia intelligenza contestuale condivisa tra le reti. Le aziende e le organizzazioni più lungimiranti hanno già iniziato a trovare e adottare nuove soluzioni per ricavare valore dai big data della supply chain.
"Ogni supply chain genera big data."
Essere consapevoli che le supply chain generano big data è il passo più semplice, ma anche il più cruciale, che un'azienda deve compiere per iniziare a trarne valore. In seguito, le aziende devono iniziare a conoscere i dati prodotti dalla loro catena di fornitura. Infine, devono utilizzare questi dati a proprio vantaggio per migliorare le operazioni, i prodotti e i servizi.
L'ostacolo maggiore per le aziende è l'identificazione dei dati giusti che costituiranno la base per l'avvio dei processi decisionali. Per superare questa sfida, è necessario conoscere meglio i dati.
Per cominciare, prendiamo in considerazione i tre tipi di dati che stiamo con cui abbiamo a che fare: dati strutturati, semi-strutturati e non strutturati.
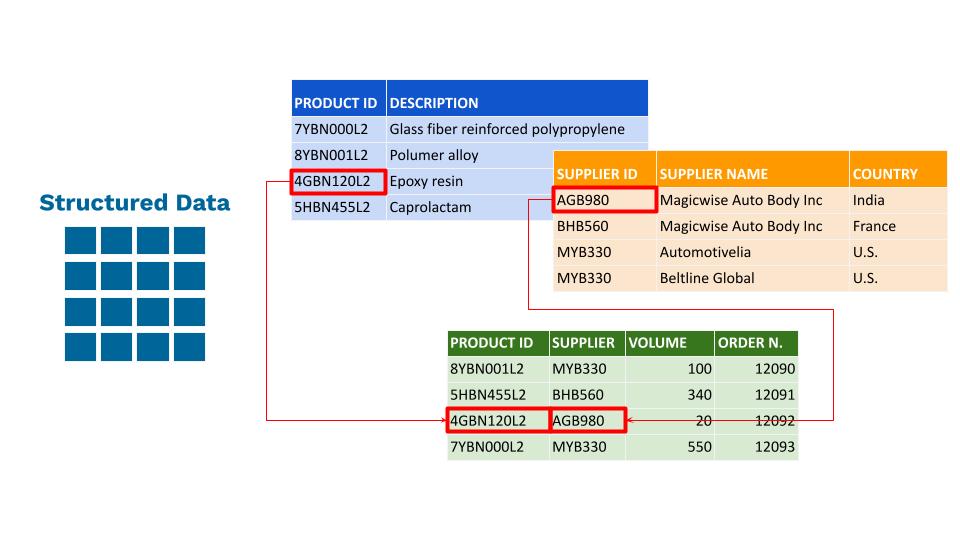
Dati strutturati
I dati strutturati fanno riferimento a formati e modelli predefiniti. Si tratta generalmente di dati tabellari rappresentati da colonne e righe in un database, dove le righe sono caratterizzate e identificate da chiavi univoche. I file Excel, i database SQL e i database ERP/TMS/WMS/CRM sono esempi comuni di dati strutturati.
Dati semi-strutturati
I dati semi-strutturati hanno attributi che assomigliano ai dati strutturati, ma non possono essere salvati in un formato rigido: non seguono il formato di un modello di dati tabellari o di database relazionali perché non hanno uno schema fisso. Tuttavia, i dati non sono completamente grezzi o non strutturati e contengono alcuni elementi strutturali come tag e metadati organizzativi che ne facilitano l'analisi. Codici HTML, grafici, tabelle, documenti XML e documenti in formato JSON sono esempi di dati semi-strutturati.

Dati non-strutturati
Questo tipo di dati non può essere memorizzato in un modello di dati tradizionale e rigido o in un database relazionale. I dati non strutturati non si possono organizzare in modo predefinito né hanno un modello di dati prestabilito. Si tratta di un insieme di informazioni testuali, ma possono contenere anche dati come numeri, date e fatti. Video, audio, dati provenienti da messaggi di testo, documenti word ed e-mail rientrano in questa categoria.
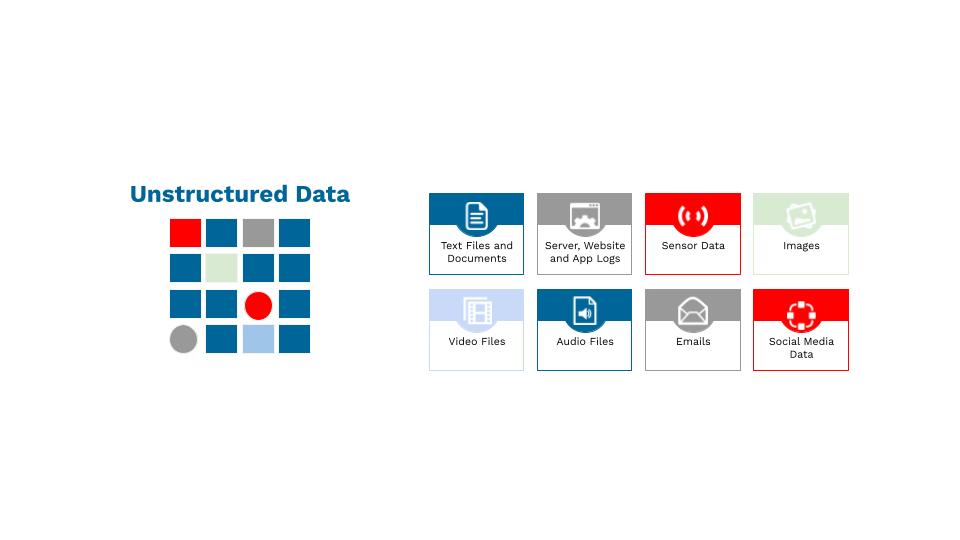
Il flusso continuo di dati arriva in queste tre forme. Sebbene sia più facile raccogliere, gestire, archiviare e interpretare i dati strutturati, secondo Gartner l'80% dei dati aziendali è costituito da dati non strutturati. Inoltre, la quantità di dati semi-strutturati e non strutturati sta crescendo molto più rapidamente rispetto ai dati strutturati. La figura seguente, che classifica le fonti di dati nella supply chain in base alla loro categoria (strutturati, semi-strutturati e non strutturati) e al loro volume e velocità, mostra molto chiaramente questa tendenza.³
"L'80% dei dati aziendali è costituito da dati non strutturati."
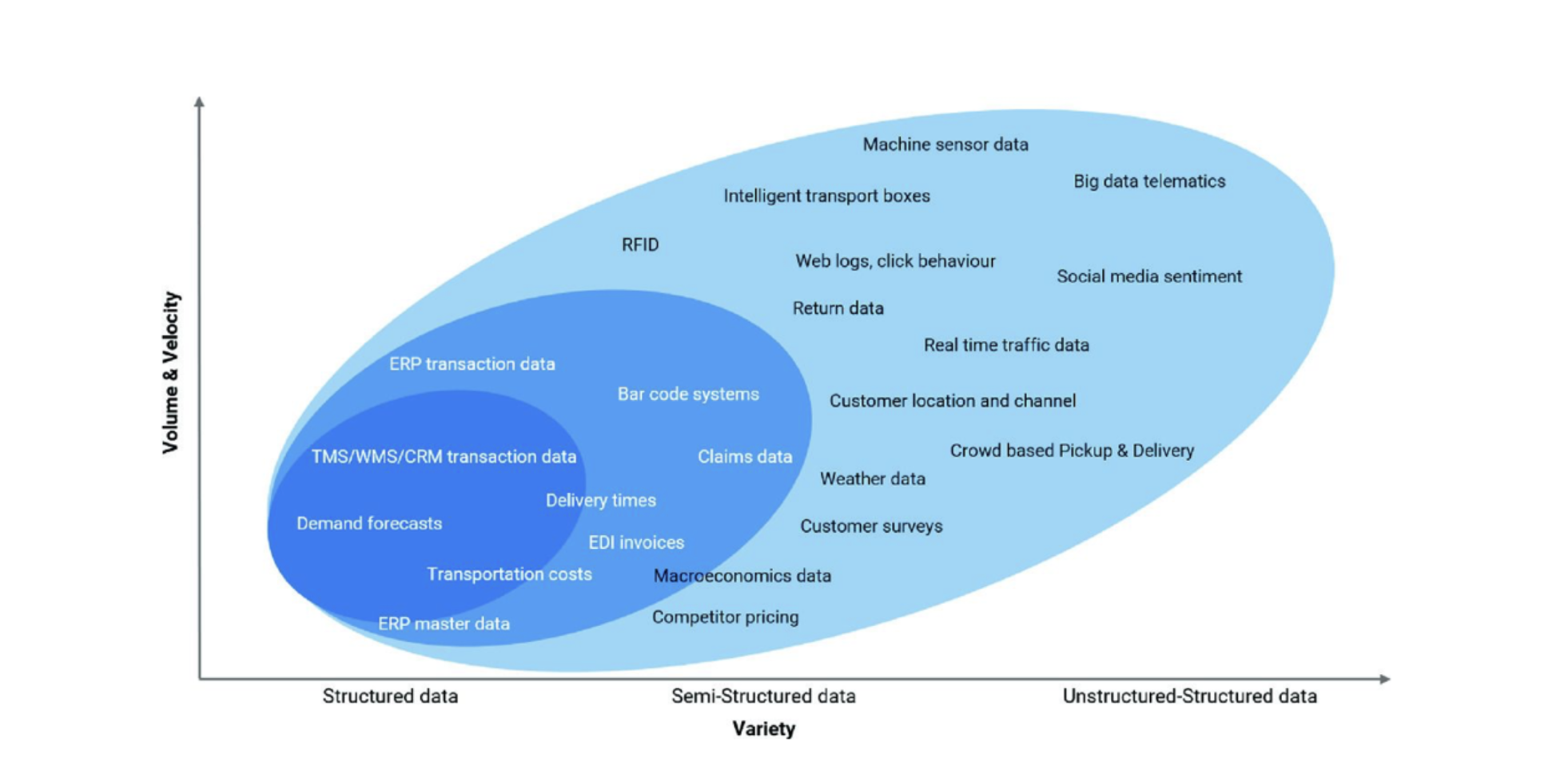
Fonte: Disrupting Logistics (Future of Business and Finance)
Quali sono le fonti dei dati della supply chain?
La domanda che sorge immediatamente è: "Allora, da dove vengono questi dati?". Esistono diverse fonti di dati, ma possiamo raggrupparle in tre categorie principali:
"Da dove vengono i dati?"
Dati interni
Le fonti primarie dei dati della supply chain sono i dati interni generati dai principali sistemi aziendali su cui le aziende eseguono le loro operazioni più importanti, come i sistemi ERP, TMS, CRM, WMS e SCM. In questi sistemi, i dati sono strutturati e archiviati in database relazionali. L'accesso e l'analisi di queste fonti di dati è solitamente semplice e non richiede competenze tecniche avanzate. Diversamente, i dati interni sono generati in modo non strutturato da e-mail, documenti, video e immagini – e questo complica la raccolta e l'analisi. In ogni caso, senza questa fonte di dati, le aziende non possono eseguire le operazioni quotidiane.
Dati del network esterno
La seconda fonte di dati è costituita dai dati di network esterni generati da fornitori, partner o clienti. Possono essere dati sui tassi di produzione, sulle statistiche di qualità e sull'affidabilità delle consegne. Poiché i dati di network esterni arrivano solitamente in modo semi-strutturato o non strutturato, è difficile raccoglierli e analizzarli. Questa fonte di dati è fondamentale per le aziende, proprio come i dati interni, perché offre ulteriore visibilità sulle operazioni e sulle supply chain di fornitori, partner o clienti strategici, aiutando a identificare le interruzioni della supply chain e a gestire i rischi.
Dati dei dispositivi
L'ultima fonte di dati raccoglie i dati rilevanti per le operazioni della supply chain. L'esempio più noto è quello dei dati generati da dispositivi e sensori utilizzati per tracciare la posizione e le condizioni delle spedizioni (ad esempio, temperatura, umidità, urti), per gestire le scorte di magazzino o per monitorare e controllare le operazioni di fabbrica. Tali dati tendono a essere raccolti in archivi, chiamati data lake, in modo non strutturato.
Sebbene queste tre siano le principali fonti di dati per la supply chain, non sono le uniche. I dati rilevanti per la supply chain possono provenire anche dalle previsioni meteorologiche (identificazione di alcune condizioni atmosferiche sulle spedizioni o sulle consegne), dalle azioni e dalle direttive politiche (identificazione di azioni importanti e modus operandi), dai feed dei social media (identificazione delle tendenze e della domanda) e dal consumo di CO2 (identificazione di azioni legate alla sostenibilità)⁴.
Come ricavare valore dai dati della supply chain?
L'enorme quantità di dati generati da queste fonti porta con sé opportunità e sfide. Come già detto, la maggior parte delle aziende è abituata ad accedere, gestire e analizzare i dati strutturati generati dai propri sistemi ERP, TMS o WMS.
Tuttavia, alcuni dei dati più critici e preziosi sono generati al di fuori di questi sistemi in forma non strutturata. Trasformare questi big data in informazioni preziose per prendere decisioni aziendali migliori può dare un importante vantaggio competitivo alle aziende⁵. Tuttavia, raggiungere questo vantaggio competitivo non è sempre facile. Ciò è dovuto a varie ragioni.
I dati sono frammentati e disconnessi
I dati delle supply chain moderne sono frammentati e scollegati. Spesso sono archiviati in applicazioni diverse e in silos. Ciò rende molto difficile sfruttare simultaneamente i dati generati da fonti diverse.
"I dati della supply chain sono frammentati e disconnessi. Sono conservati e gestiti in silos."
Si pensi a un'azienda che spedisce prodotti a temperatura controllata verso destinazioni estere e che riceve i dati sullo stato della spedizione da un'applicazione e quelli sulla temperatura da un'altra. Inoltre, gestisce gli ordini di acquisto con il suo sistema ERP. Questo è un esempio chiarissimo di disconnessione e frammentazione dei dati.
In questi casi diventa problematico sfruttare i dati esterni e condividere informazioni essenziali con partner commerciali, fornitori e clienti.
I dati sono spesso latenti e duplicati
Un altro ostacolo per le aziende che vogliono trarre valore dai dati della supply chain è rappresentato dai dati latenti e duplicati. È importante capire che la vera assenza di dati o di una fonte di dati si manifesta in pochissime occasioni. Il problema più comune è la latenza: le aziende non sanno dove trovare dati specifici su un determinato processo o prodotto. Questo può essere un vero e proprio impedimento sia per la corretta esecuzione delle attività operative sia per l'implementazione di strategie data-driven.
"Le aziende non sanno dove trovare dati specifici su un determinato processo o prodotto e spesso li copiano e li duplicano in sistemi diversi."
Un altro ostacolo simile è la duplicazione o la copia dei dati in sistemi diversi. A volte le aziende sono costrette a destinare risorse preziose all'inserimento manuale dei dati o a copiare i dati da un sistema all'altro per portare avanti le attività operative. Ad esempio, la pianificazione della produzione, il WMS, la pianificazione delle scorte e l'ERP devono tutti ottenere una parte dei dati sui materiali. Pertanto, alcuni dati vengono replicati in questi sistemi e, nel migliore dei casi, mantenuti sincronizzati. Questa sincronizzazione può essere eseguita manualmente da qualcuno o automaticamente senza interazione umana.
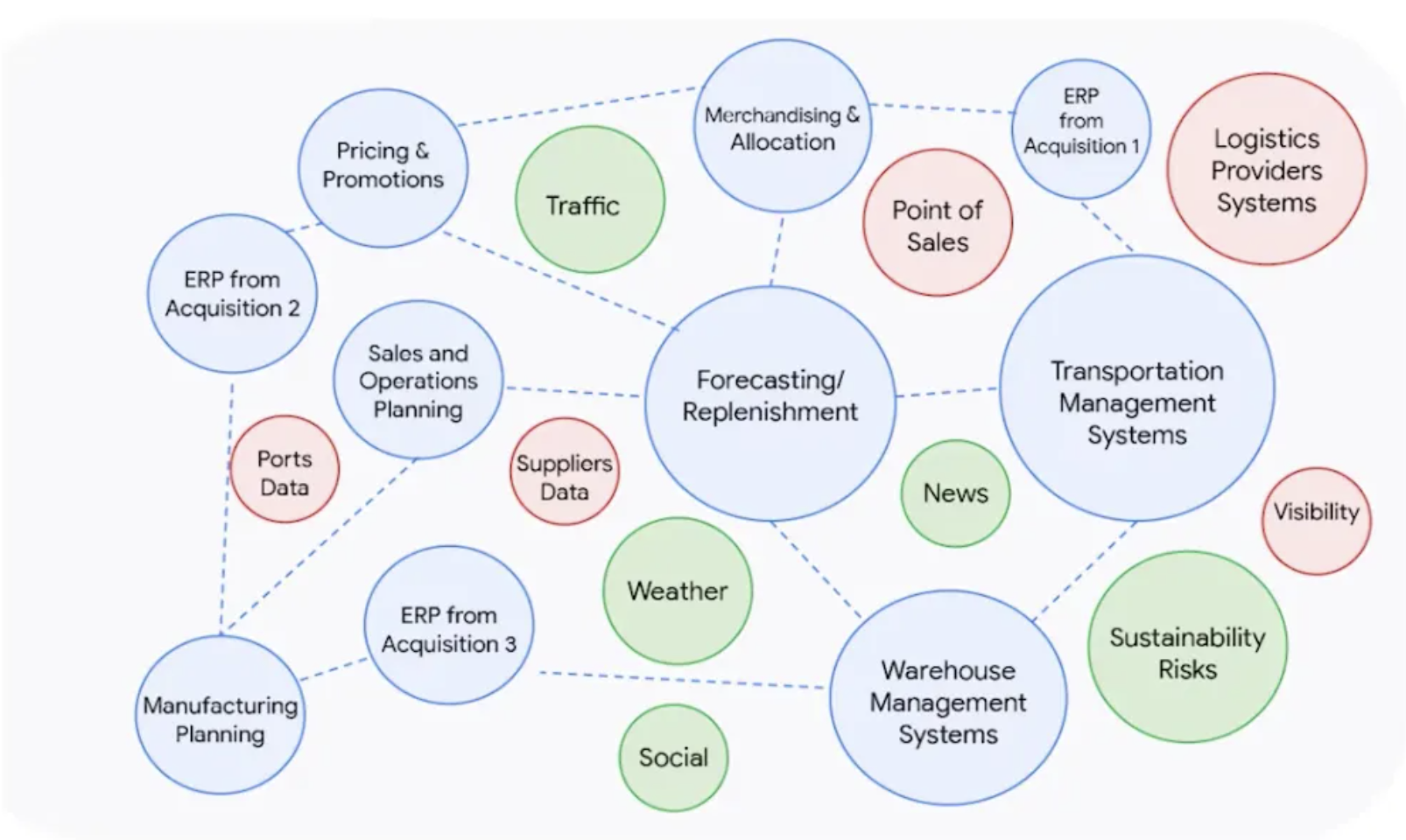
Fonte: Google for supply chain
I metodi tradizionali non sono sufficienti per analizzare i big data della supply chain
I metodi tradizionali analizzano i dati generati in un periodo di tempo o i dati di un evento specifico dopo che l'evento si è già verificato o il periodo di tempo si è concluso. Considerando il volume, la velocità e la diversità dei big data, questi metodi non sono adatti a creare approfondimenti di valore. È per questo motivo che oggi le analisi avvengono in tempo reale e i risultati vengono presentati quasi istantaneamente.
La maggior parte dei manager della supply chain o della logistica, anche quelli con un background tecnico, ha poca o nessuna esperienza con questo tipo di analisi dei dati. Per estrarre valore dai big data, le aziende devono adottare tecnologie e metodi adeguati.
"Oggi le analisi avvengono in tempo reale e i risultati vengono presentati quasi istantaneamente."
Infine, la creazione di valore dai dati della supply chain inizia con il superamento di questi tre ostacoli iniziali e accelera con l'implementazione di pratiche di aggregazione, interoperabilità, automazione e analisi dei dati.
Aggregazione, integrazione e interoperabilità dei dati
I silos di dati nella supply chain sono una delle principali sfide al processo decisionale data-driven e un grande ostacolo alla crescita aziendale. Sapere esattamente cosa sono, come influenzano il vostro team e la vostra azienda e come risolverli può aiutare a superare questa sfida.
Nell'ultimo decennio, gli sviluppi tecnologici hanno reso possibile la combinazione di diversi tipi di dati provenienti da fonti diverse e l'eliminazione dei blocchi creati dai silos di dati. Ci sono tre concetti importanti e comunemente utilizzati che si sentono spesso quando si parla di abbattere i silos di dati.
L’aggregazione di dati, che nel contesto della supply chain significa raccogliere i dati della supply chain da più fonti e inserirli in gruppi logici (set di dati) ai fini della modellazione.
L'integrazione di dati fa riferimento al processo di raccolta di risultati da più set di dati.
Infine, l'interoperabilità dei dati significa che un sistema è in grado di lavorare agevolmente con altri sistemi. Nel contesto della supply chain, significa che i sistemi di ciascun partner commerciale sono in grado di comunicare e di comprendersi a vicenda e possono quindi lavorare insieme per fare qualcosa di utile.
L'aggregazione, l'integrazione e l'interoperabilità dei dati sono più efficaci se utilizzate insieme in armonia. Queste tre pratiche aiutano le aziende a ricavare informazioni da una versione sintetica dei loro dati. La qualità dell'analisi finale dei dati dipende dall'accuratezza e dalla completezza dell'aggregazione dei dati.
Pertanto, le aziende che mirano a ottenere informazioni da grandi quantità di dati devono capire come raccogliere efficacemente i dati attraverso l'aggregazione e analizzarli attraverso l'integrazione. Le aziende possono applicare queste pratiche ai dati generati sia internamente sia esternamente. Quest'ultimo aspetto ci porta alla discussione sullo scambio di dati e informazioni tra aziende.
"La qualità dell'analisi dei dati dipende dall'accuratezza dell'aggregazione dei dati."
Perché è necessario aggregare i dati interni?
Le aziende non sempre hanno una comprensione completa dei dati generati internamente, e di conseguenza non hanno una visione chiara e completa delle loro operazioni. Ciò può essere causato dall'assenza di comunicazione tra i diversi dipartimenti e team o da sistemi diversi perché non collegati tra loro. Di conseguenza, i dati non possono passare facilmente da un reparto all'altro dell'organizzazione. Questo accade soprattutto perché non esistono strumenti adeguati per realizzare questa connessione vitale e attivare un flusso continuo di informazioni.
Non è insolito che un manager della supply chain controlli i dettagli dell'inventario sul WMS dell'azienda, passando al TMS per controllare i dettagli della distribuzione e convalidare gli aspetti economici sull'ERP. La mancanza di un flusso di dati e di una sincronizzazione in tempo reale tra questi sistemi può causare gravi inconvenienti operativi e commerciali, come una pianificazione dei trasporti errata (o non ottimale), ritardi e reclami dei clienti.
Per questo è importante parlare di aggregazione, integrazione e interoperabilità dei dati generati internamente. A seconda delle dimensioni dell'azienda, i dati possono essere raccolti e aggregati da diversi reparti, siti produttivi, magazzini, centri di distribuzione o negozi della stessa azienda. Questo flusso di dati in tempo reale eliminerà i silos nei sistemi aziendali e sincronizzerà tutti i dati, consentendo all'impresa di gestire con successo le operazioni della supply chain, ridurre gli errori e aumentare l'efficienza.
Come aggregare i dati esterni?
Poiché si parla di flusso continuo di dati in tempo reale, le pratiche di aggregazione, integrazione e interoperabilità dei dati si riferiscono direttamente alla condivisione delle informazioni tra partner commerciali, fornitori e clienti. Le asimmetrie informative possono avere un impatto negativo sulle operazioni aziendali, sugli sforzi di trasparenza della supply chain e sulle relazioni con i partner commerciali, oltre a ostacolare gli sforzi di conformità alle normative.
Trasmissione manuale
Tradizionalmente, le aziende trasmettono i dati che vogliono condividere con i propri fornitori e clienti inviando via e-mail o dei fogli excel o direttamente le informazioni, oppure telefonando. Oggi questi metodi stanno perdendo popolarità perché causano perdita di informazioni, confusione e inefficienze operative.
Integrazione diretta
All'inizio degli anni 2010 si è verificata l'interazione diretta tra i sistemi. In queste applicazioni, i sistemi informatici erano direttamente integrati tra loro, il che significa che gli input provenienti da un sistema fornivano aggiornamenti all'altro sistema. Questa automatizzazione ha creato una condivisione delle conoscenze tempestiva e senza soluzione di continuità tra le parti e ha risolto i problemi causati dagli aggiornamenti manuali. Tuttavia, collegare i sistemi informatici, soprattutto per integrare tutti i partner commerciali, non è sempre la soluzione ottimale, perché la varietà di parti e la quantità di dati coinvolti nel processo comportano costi di integrazione elevati e complicazioni.
Soluzioni di aggregazione (EDI, API…)
Una soluzione creativa per l'aggregazione dei dati è quella di consentire a ciascuna parte di inviare elementi di dati predefiniti a uno strumento di aggregazione dei dati, che a sua volta funge da archivio. Quando si verificano eventi, le parti coinvolte trasmettono i loro aggiornamenti allo strumento di aggregazione: possono accedere al repository ed eseguire le proprie interrogazioni per rispondere alle domande e monitorare i progressi. Sia lo scambio elettronico Electronic Data Interchange (EDI) e le tecnologie Application Programming Interface (API) applicano questa logica. La differenza è che le trasmissioni API sono tipicamente basate su Internet o sul cloud, forniscono aggiornamenti in tempo reale e possono gestire lo scambio di dati tra sistemi diversi in pochi secondi, mentre l'EDI stabilisce una connessione solo tra due sistemi EDI e lo scambio di dati richiede più tempo⁶. Ciò che l'EDI impiega da 30 minuti a 2 ore per caricare, l'API può farlo in pochi minuti.
"Le pratiche di aggregazione, integrazione e interoperabilità dei dati si riferiscono direttamente alla condivisione di informazioni tra partner commerciali, fornitori e clienti."
Tecnologie che abilitano l'automazione e l'analisi dei dati
Esistono grandi opportunità e un enorme potenziale di ottimizzazione se un'azienda è in grado di memorizzare, aggregare e combinare i dati e poi utilizzare i risultati per eseguire analisi approfondite. Il problema principale per le aziende è come scegliere il giusto stack tecnologico e il giusto approccio per creare soluzioni data-driven in modo efficiente.
Contrariamente a quanto si pensa, le soluzioni di analisi avanzata, l'Intelligenza Artificiale e le tecnologie di Machine Learning non sono accessibili solo alle aziende tecnologiche o alle grandi società. L'estrazione di informazioni dai dati sta migliorando, così come i software disponibili per applicare tecniche altamente sofisticate. Grazie ad alcuni operatori del mercato, queste tecnologie e soluzioni stanno diventando la spina dorsale dei processi digitali.
Un esempio in real-life del Machine Learning
Esistono molte tecniche e tecnologie essenziali per analizzare i dati, come le query SQL, l'analisi dei big data, la ricerca full-text, l'analisi in tempo reale e il machine learning. Quest'ultimo, ad esempio, sviluppa algoritmi che consentono ai computer di evolvere i comportamenti sulla base di dati empirici. In questo modo, gli algoritmi imparano automaticamente a riconoscere modelli complessi e a prendere decisioni intelligenti sulla base dei dati.
Pensiamo alle richieste commerciali che riceviamo via e-mail. Se applichiamo algoritmi intelligenti e li addestriamo con un numero sufficiente di esempi, questi algoritmi saranno in grado di identificare modelli ed evidenziare ed estrarre informazioni come il nome del mittente, le informazioni di contatto, le informazioni sul prodotto, ecc. e di comunicarle al nostro sistema ERP. Tutto ciò avverrà automaticamente e in pochi secondi, senza alcuna interazione umana.
"Gli algoritmi intelligenti imparano automaticamente a riconoscere modelli complessi e a prendere decisioni intelligenti sulla base dei dati."
Quali sono i reali vantaggi dell'analisi dei dati della supply chain?
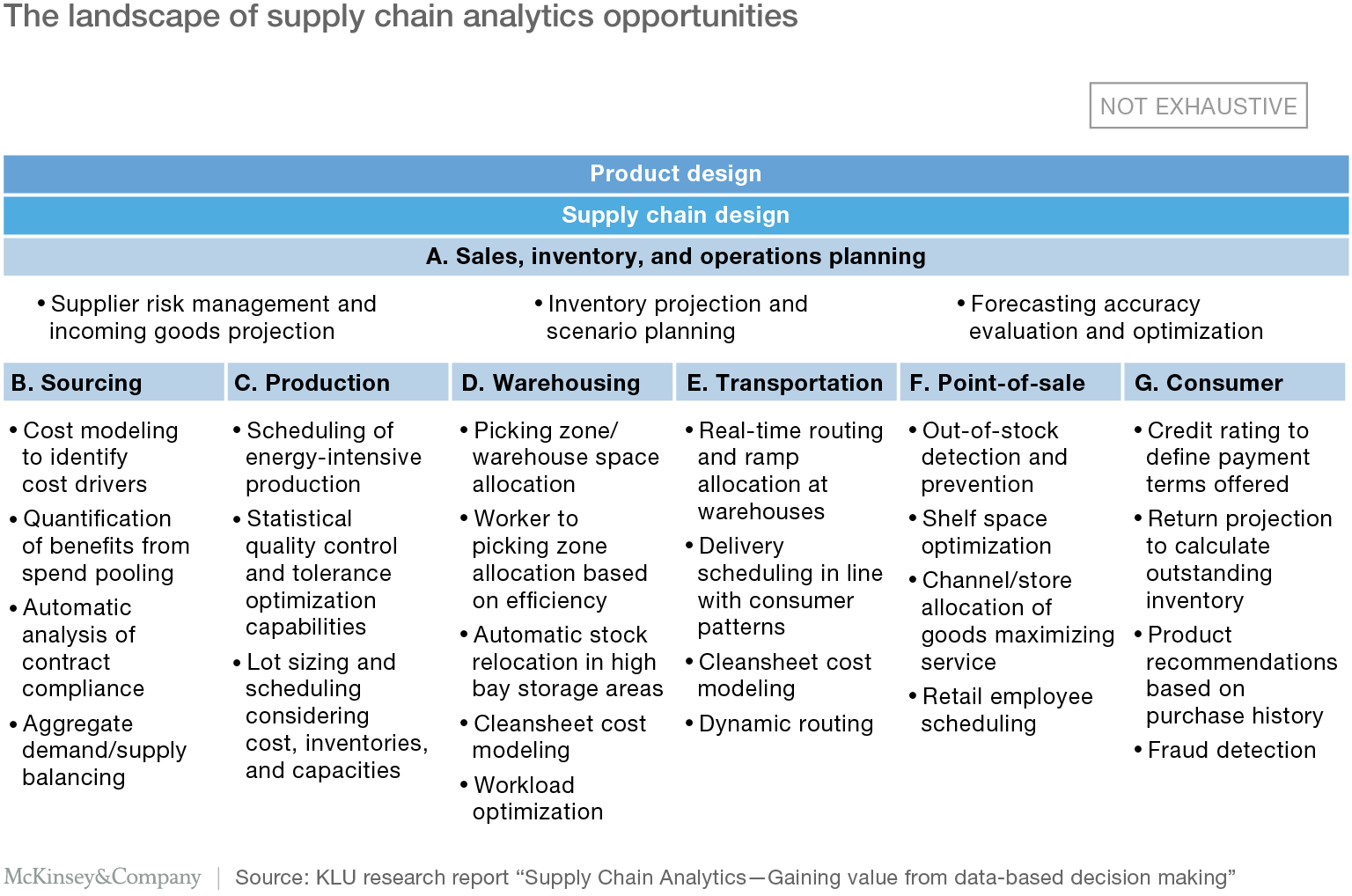
Jan Sigmund condivide una figura davvero interessante nel libro Disrupting Logistics, fornendo una panoramica di dove il processo decisionale basato sui dati attraverso l'analisi della supply chain genera valore lungo la catena di approvvigionamento⁷.

Fonte: Disrupting Logistics (Future of Business and Finance)
Oggi, la figura mostra fondamentalmente l'importanza di pensare in modo strategico alla supply chain, dal momento che i prodotti, i clienti e le esigenze del mercato cambiano costantemente. Secondo l'autore, l'enorme quantità di dati raccolti lungo la catena offre alle aziende grandi opportunità per ottimizzare il design della rete, le decisioni strategiche di approvvigionamento e i flussi di prodotto in modo permanente.
Un report pubblicato dal McKinsey Global Institute afferma che le opportunità di analisi della supply chain possono essere trovate in tutte le fasi della catena di fornitura, come la pianificazione, la produzione, il magazzino, il trasporto, il punto vendita e il consumatore⁸.
Ad esempio, nel settore dei trasporti, le aziende utilizzano già le tecnologie GPS per ridurre i tempi di attesa, assegnando le baie di magazzino in tempo reale. Hanno anche iniziato a implementare tecnologie di ottimizzazione dei percorsi, selezionando il percorso migliore per le consegne. Questo aiuta a ridurre gli spostamenti inutili e, in ultima analisi, a tagliare i costi.
"Le opportunità di analisi della supply chain possono essere trovate in tutte le fasi della catena di fornitura, come la pianificazione, la produzione, il magazzino, il trasporto, il punto vendita e il consumatore."
4 modi per creare valore dai big data della supply chain
1. Creare trasparenza
Rendere i dati rilevanti più facilmente accessibili alle parti interessate può abbattere i silos tra i diversi dipartimenti, ridurre i tempi di ricerca e di elaborazione e migliorare la qualità. La collaborazione tra i partner della supply chain e la condivisione dei dati possono essere utilizzate per la modellazione predittiva e il processo decisionale. La condivisione di informazioni importanti, all'interno dell'azienda, tra le diverse divisioni o all'esterno, con fornitori, clienti e partner, aumenta la trasparenza della supply chain.
La trasparenza alimenta il processo decisionale, consolida le capacità decisionali e le rende più efficienti. Ad esempio, la completa visibilità e trasparenza dei dati sulla domanda e sull'offerta può guidare la pianificazione dei fornitori e delle scorte. Ciò può influenzare positivamente la pianificazione e l'esecuzione delle operazioni logistiche. In pratica si crea un effetto domino: se il processo decisionale del reparto di sourcing è facilitato, il carico di lavoro dei reparti di magazzino e logistica sarà migliorato e ottimizzato.
Le aziende possono creare un valore reale per le imprese grazie al solido legame tra i dati della supply chain, la trasparenza e l'efficienza del processo decisionale.
2. Migliorare le performance
La raccolta di dati più precisi e dettagliati sulle performance consente alle aziende di comprendere le cause di alcuni problemi e di definire nuove strategie per migliorare le prestazioni. Questo può essere applicato in vari casi, dagli inventari dei prodotti alla pianificazione dei percorsi. La pianificazione dei percorsi, ad esempio, se effettuata manualmente può rappresentare una sfida per l'azienda. Questo perché comporta molti vincoli, tra cui tempo, risorse, operatore, condizioni, comunicazione e tecnologia. I metodi manuali o statici possono causare costosi errori umani, mancanza di rapidità di risposta e di capacità di reazione immediata. Per eliminare questi vincoli, si sfruttano i dati storici e in tempo reale. Trovare il percorso migliore permette alle aziende di risparmiare tempo su soste inutili e inefficienti, di utilizzare le risorse in modo efficiente, di risparmiare tempo e di migliorare continuamente l'efficienza operativa.
Quando c'è un problema di performance da risolvere, è fondamentale conoscere il problema esatto. Solo l'accesso ai dati pertinenti e l'utilizzo di funzionalità di analisi dei dati possono aiutare a identificare il problema alla radice. Inoltre, questo porta tutte le parti interessate nella stessa direzione, gestendo le aspettative e ottenendo risultati.
3. Ridurre le attività time-consuming
Le analisi avanzate possono ridurre le attività manuali che richiedono tempo e lavoro. Secondo Gartner, i lavoratori sprecano dal 20% al 30% della loro settimana lavorativa per gestire documenti o informazioni basate su documenti⁹. L'uso di algoritmi intelligenti e l'automazione possono ottimizzare i processi aziendali e migliorare l'accuratezza o i tempi di risposta.
L'automazione delle attività che richiedono tempo, dall'elaborazione degli ordini alla spedizione automatizzata, può migliorare l'efficienza, ridurre gli errori umani, aumentare le prestazioni e la velocità della supply chain e risparmiare tempo e denaro nel lungo periodo.
Il rinnovamento dei processi esistenti con processi automatizzati non sostituisce necessariamente l'impegno umano, ma aiuta le aziende a snellire le operazioni e ad aumentare la produttività. In questo modo le aziende possono destinare le loro preziose risorse ad attività più importanti e investire maggiormente nello sviluppo dei prodotti, nel marketing e in altre iniziative cruciali.
4. Innovare prodotti e servizi
L'analisi dei dati della supply chain consente alle aziende di creare nuovi prodotti e servizi, di innovare quelli esistenti e di portare il proprio business al passo con i tempi. Riunire gli input interni ed esterni è fondamentale per creare nuovi prodotti e realizzare una gestione dei prodotti completa. Senza l'analisi, lo sviluppo del prodotto si riduce alle basi dello sviluppo di un'idea di prodotto, della sua implementazione in base al risultato finale e del non considerare se soddisfa o supera le aspettative dei clienti.
L'analisi dei big data nella supply chain semplifica il processo di sviluppo del prodotto. Si concentra sui dati giusti da studiare e riduce il tempo dedicato ai notevoli tentativi ed errori, per lo più guidati dai team di ricerca e sviluppo.
I produttori possono utilizzare i dati ottenuti dall'uso di prodotti reali per migliorare lo sviluppo della prossima generazione di prodotti e per creare offerte innovative di servizi post-vendita. I rivenditori possono analizzare i dati relativi ai punti vendita (POS), alle scorte e ai volumi di produzione per determinare quali prodotti mettere in vendita e quando lanciare nuove offerte.
Conclusioni
Oggi un numero sempre maggiore di persone, aziende, dispositivi, sensori e sistemi è collegato da reti digitali. La capacità di generare, comunicare, condividere e accedere ai dati è fortemente influenzata da questa tendenza. Oltre 30 milioni di nodi sensore collegati in rete sono oggi presenti nei settori dei trasporti, dell'automotive, dell'industria, dei servizi pubblici e della vendita al dettaglio. Il numero di questi sensori aumenta a un ritmo di oltre il 30% all'anno. Nel prossimo futuro, i big data e l'analisi dei dati della supply chain diventeranno un vantaggio competitivo fondamentale per le aziende. I primissimi utilizzatori hanno già iniziato a creare capacità di analisi e automazione dei dati.
Note
1- OECD Glossary of Statistical Terms. OECD. 2008.
2- Disrupting Logistics (Future of Business and Finance) (p. 165), Springer International Publishing. Kindle Edition.
3- Ibidem.
4- Ivi, (p. 169).
5- Ibidem
6- Netsuite, Supply Chain Analytics: What It Is & Why It Matters
7- Disrupting Logistics (Future of Business and Finance), (p. 170).
8- MGI: Big data and the supply chain: The big-supply-chain analytics landscape (Part 1)
 Il Regolamento UE sulle informazioni elettroniche sul trasporto merci
Il Regolamento UE sulle informazioni elettroniche sul trasporto merci Come gestire i dati sparsi in diverse piattaforme?
Come gestire i dati sparsi in diverse piattaforme? Quali strumenti usare per accedere ai dati rapidamente?
Quali strumenti usare per accedere ai dati rapidamente? Abbatti silos di dati e rischi aziendali con una piattaforma digitale
Abbatti silos di dati e rischi aziendali con una piattaforma digitaleContatti
Sede Legale
Via S. Quasimodo 42
40013 Castel Maggiore (BO)
Sede Operativa
Via B. Quaranta, 40
20139 Milano
P.I. 03444511202
Seguici su

