Cómo mejorar la cadena de suministro con la agregación de datos
- ¿Qué es el big data de la cadena de suministro?
- ¿Cuáles son las fuentes de datos de la cadena de suministro?
- ¿Cómo extraer el valor de los datos de la cadena de suministro?
- Agregación, integración e interoperabilidad de datos
- Tecnologías que permiten la automatización y el análisis de datos
- ¿Cuáles son los beneficios reales del análisis de datos de la cadena de suministro?
- 4 ormas de crear valor a partir del big data de la cadena de suministro
- Conclusiones
- Notas
Indice contenuti

Vivimos en un mundo impulsado por los datos. En la última década, los datos se han convertido en sinónimo de valor y en el recurso más valioso del mundo. Cuando se trata de tomar decisiones para nuestro negocio, tenemos que basarnos en los datos. Es imposible que las organizaciones tomen decisiones precisas sin utilizarlos.
"Para tomar decisiones precisas se necesitan datos."
Los datos se definen como la parte más pequeña pero más importante del proceso de toma de decisiones, ya que sin ellos no puede haber una base para el razonamiento o la discusión¹. Esta amplia definición nos da una idea de por qué son tan cruciales para las cadenas de suministro. No es ningún secreto que hoy en día se producen enormes cantidades de datos cada hora en todas las etapas de la cadena de suministro². Esto no es una mera exageración. De hecho, esta es la razón por la que cuando hablamos de cadenas de suministro, hablamos de "big data". Al recopilar, analizar, armonizar e interpretar estos datos, una empresa puede crear soluciones basadas en datos y mejorar la eficiencia operativa, los productos y los servicios.
¿Qué es el big data de la cadena de suministro?
El término "big data" hace referencia a conjuntos de datos demasiado grandes o complejos para ser tratados con los métodos de procesamiento tradicionales. Se asocian a tres conceptos clave: volumen, variedad y velocidad. El término se utiliza desde principios de los años 90. A principios de la década de 2000, gracias a las extraordinarias posibilidades de recopilación y análisis de datos que ofrece Internet, el término se hizo cada vez más popular y se extendió por varios sectores.
No es difícil entender su penetración en el contexto de la cadena de suministro. En todas las etapas de la cadena de suministro, desde la planificación hasta la entrega final, se produce continuamente una gran cantidad de datos (volumen). Además de los grandes volúmenes, estos datos se generan en formatos heterogéneos (variedad) y crecen rápidamente (velocidad).
Por lo tanto, no es erróneo decir que toda cadena de suministro genera big data. Sin duda, es el motor de las cadenas de suministro actuales. Los macrodatos están proporcionando a las cadenas de suministro una mayor precisión, claridad y comprensión de los datos y están dando lugar a una inteligencia contextual más amplia que se comparte en todas las redes. Las empresas y organizaciones con visión de futuro ya han empezado a encontrar y adoptar nuevas soluciones para obtener valor de los big data de la cadena de suministro.
"Toda cadena de suministro genera big data."
Ser consciente de que las cadenas de suministro generan big data es el paso más sencillo, pero también el más crucial, que debe dar una empresa para empezar a obtener valor de ellos. A continuación, las empresas deben empezar a conocer los datos que generan sus cadenas de suministro. Por último, deben utilizar estos datos en su beneficio para mejorar las operaciones, los productos y los servicios.
El mayor obstáculo para las empresas es identificar los datos correctos que constituirán la base para iniciar los procesos de toma de decisiones. Para superar este reto, es necesario conocer mejor los datos.
Para empezar, consideremos los tres tipos de datos que tratamos: datos estructurados, semiestructurados y no estructurados.
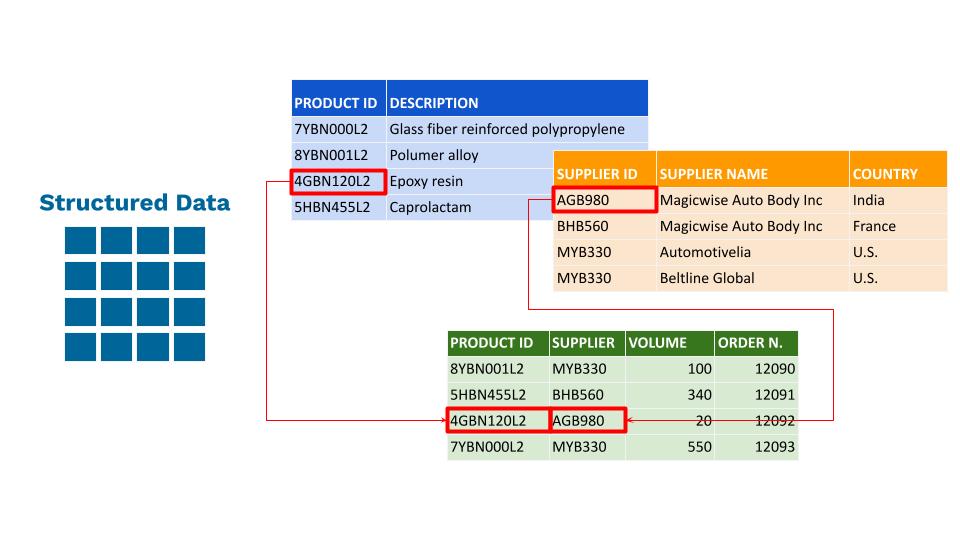
Datos estructurados
Los datos estructurados se refieren a formatos y modelos predefinidos. Por lo general, se trata de datos tabulares representados por columnas y filas en una base de datos, donde las filas se caracterizan e identifican por claves únicas. Los archivos de Excel, las bases de datos SQL y las bases de datos ERP/TMS/WMS/CRM son ejemplos comunes de datos estructurados.
Datos semiestructurados
I dati semi-strutturati hanno attributi che assomigliano ai dati strutturati, ma non possono essere salvati in un formato rigido: non seguono il formato di un modello di dati tabellari o di database relazionali perché non hanno uno schema fisso. Tuttavia, i dati non sono completamente grezzi o non strutturati e contengono alcuni elementi strutturali come tag e metadati organizzativi che ne facilitano l'analisi. Los datos semiestructurados tienen atributos que se asemejan a los datos estructurados, pero no pueden almacenarse en un formato rígido: no siguen el formato de un modelo de datos tabulares o de una base de datos relacional porque no tienen un esquema fijo. Sin embargo, los datos no están completamente crudos o desestructurados y contienen ciertos elementos estructurales como etiquetas y metadatos organizativos que facilitan su análisis. Los códigos HTML, los gráficos, las tablas, los documentos XML y los documentos en formato JSON son ejemplos de datos semiestructurados.

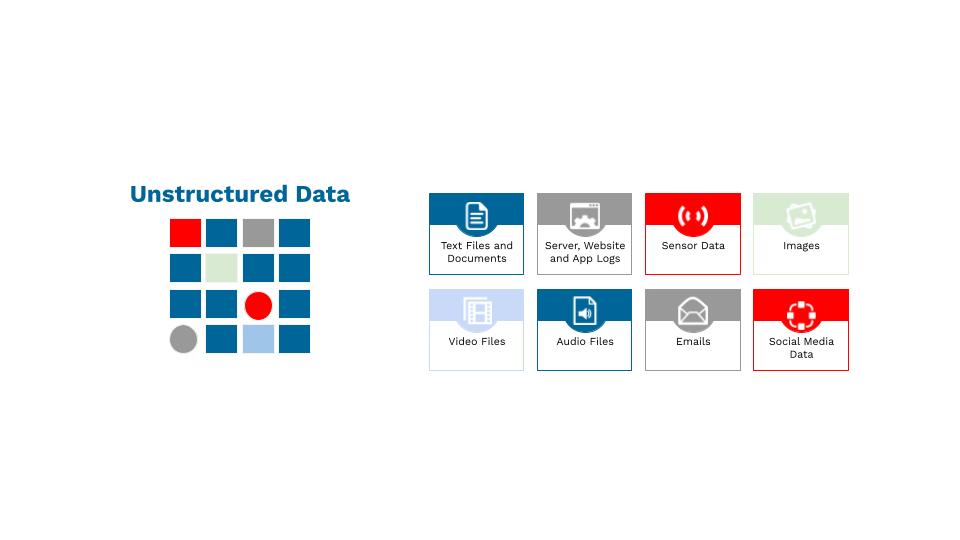
Datos no estructurados
Este tipo de datos no puede almacenarse en un modelo de datos tradicional y rígido o en una base de datos relacional. Los datos no estructurados no pueden organizarse de forma predefinida ni tienen un modelo de datos predefinido. Es una colección de información textual, pero también puede contener datos como números, fechas y hechos. Los vídeos, el audio, los datos de los mensajes de texto, los documentos de Word y los correos electrónicos entran en esta categoría.
El flujo continuo de datos se presenta de estas tres formas. Aunque es más fácil recopilar, gestionar, almacenar e interpretar datos estructurados, según Gartner, el 80% de los datos empresariales son datos no estructurados. Además, la cantidad de datos semiestructurados y no estructurados crece mucho más rápido que los estructurados. La figura siguiente, que clasifica las fuentes de datos en la cadena de suministro según su categoría (estructurados, semiestructurados y no estructurados) y su volumen y velocidad, muestra esta tendencia muy claramente.³
"El 80% de los datos corporativos son datos no estructurados."
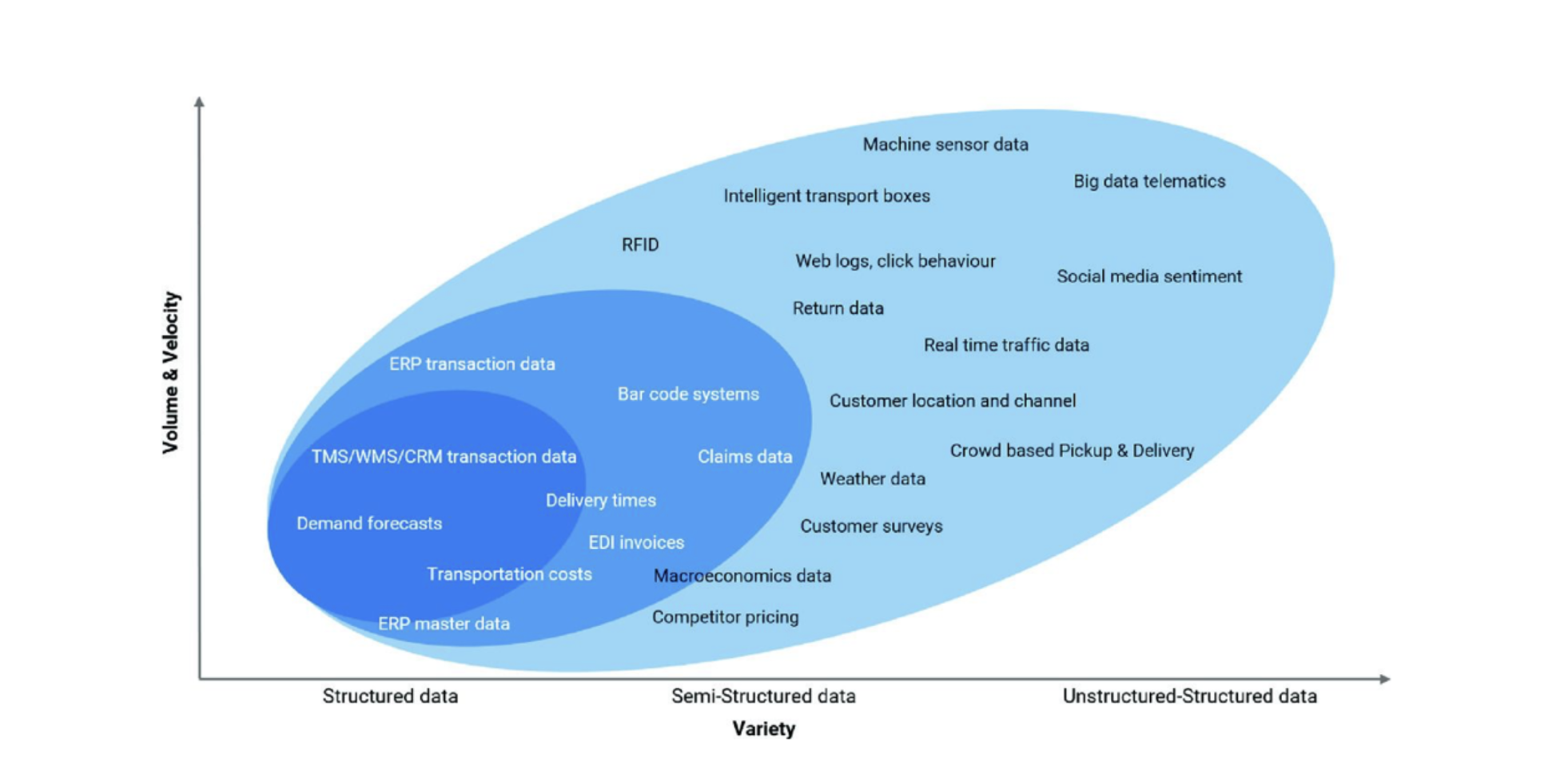
Fuente: Disrupting Logistics (Future of Business and Finance)
¿Cuáles son las fuentes de datos de la cadena de suministro?
La pregunta que surge inmediatamente es: "¿Y de dónde vienen estos datos?". Hay diferentes fuentes de datos, pero podemos agruparlas en tres categorías principales:
"¿De dónde provienen los datos?"
Datos internos
Las principales fuentes de datos de la cadena de suministro son los datos internos generados por los principales sistemas empresariales con los que las empresas realizan sus operaciones más importantes, como los sistemas ERP, TMS, CRM, WMS y SCM. En estos sistemas, los datos se estructuran y almacenan en bases de datos relacionales. El acceso y análisis de estas fuentes de datos suele ser sencillo y no requiere conocimientos técnicos avanzados. En cambio, los datos internos se generan de forma desestructurada a partir de correos electrónicos, documentos, vídeos e imágenes, lo que complica su recogida y análisis. En cualquier caso, sin esta fuente de datos, las empresas no pueden realizar operaciones cotidianas.
Datos de la red externa
La segunda fuente de datos son los datos de la red externa generados por proveedores, socios o clientes. Pueden ser datos sobre los índices de producción, las estadísticas de calidad y la fiabilidad de las entregas. Dado que los datos de las redes externas suelen llegar de forma semi estructurada o desestructurada, es difícil recogerlos y analizarlos. Esta fuente de datos es crucial para las empresas, al igual que los datos internos, porque proporciona una visibilidad adicional de las operaciones y las cadenas de suministro de los proveedores, socios o clientes estratégicos, lo que ayuda a identificar las interrupciones de la cadena de suministro y a gestionar los riesgos.
Datos de los dispositivos
La última fuente de datos recoge datos relevantes para las operaciones de la cadena de suministro. El ejemplo más conocido son los datos generados por dispositivos y sensores utilizados para rastrear la ubicación y el estado de los envíos (por ejemplo, temperatura, humedad, golpes), para gestionar el inventario o para supervisar y controlar las operaciones de la fábrica. Estos datos tienden a recogerse en archivos, llamados lagos de datos, de forma no estructurada.
Aunque estas tres son las principales fuentes de datos para la cadena de suministro, no son las únicas. Los datos relevantes de la cadena de suministro también pueden provenir de las previsiones meteorológicas (identificación de determinadas condiciones meteorológicas en los envíos o entregas), de las acciones y directivas políticas (identificación de acciones importantes y modus operandi), de los feeds de las redes sociales (identificación de tendencias y demanda) y del consumo de CO2 (identificación de acciones relacionadas con la sostenibilidad)⁴.
¿Cómo extraer el valor de los datos de la cadena de suministro?
La enorme cantidad de datos generados por estas fuentes trae consigo tanto oportunidades como desafíos. Como ya se ha mencionado, la mayoría de las empresas están acostumbradas a acceder, gestionar y analizar los datos estructurados generados por sus sistemas ERP, TMS o WMS.
Sin embargo, algunos de los datos más críticos y valiosos se generan fuera de estos sistemas en forma no estructurada. Convertir este big data en información valiosa para tomar mejores decisiones empresariales puede dar a las empresas una importante ventaja competitiva⁵. Sin embargo, conseguir esta ventaja competitiva no siempre es fácil. Esto se debe a varias razones.
Los datos son fragmentos desconectados
Los datos de las cadenas de suministro modernas están fragmentados y desconectados. A menudo se almacenan en diferentes aplicaciones y en silos. Esto hace que sea muy difícil explotar los datos generados por diferentes fuentes simultáneamente.
“Los datos de la cadena de suministro están fragmentados y desconectados. Se almacenan y gestionan en silos."
Piense en una empresa que envía productos con temperatura controlada a destinos extranjeros y que recibe datos sobre el estado del envío de una aplicación y datos sobre la temperatura de otra. Además, gestiona los pedidos de compra con su sistema ERP. Este es un ejemplo muy claro de desconexión y fragmentación de datos.
En estos casos, resulta problemático explotar los datos externos y compartir la información esencial con los socios comerciales, los proveedores y los clientes.
Los datos suelen estar escondidos y duplicados
Otro obstáculo para las empresas que quieren obtener valor de los datos de la cadena de suministro son los datos escondidos y duplicados. Es importante darse cuenta de que la verdadera ausencia de datos o de una fuente de datos se produce en muy pocas ocasiones. El problema más común es la latencia: las empresas no saben dónde encontrar datos específicos sobre un determinado proceso o producto. Esto puede ser un verdadero impedimento tanto para la correcta ejecución de las actividades operativas como para la aplicación de estrategias basadas en datos.
"Las empresas no saben dónde encontrar datos específicos sobre un determinado proceso o producto y a menudo los copian y duplican en diferentes sistemas."
Otro obstáculo similar es la duplicación o copia de datos en diferentes sistemas. A veces, las empresas se ven obligadas a dedicar valiosos recursos a la introducción manual de datos o a copiarlos de un sistema a otro para llevar a cabo actividades operativas. Por ejemplo, la planificación de la producción, el SGA, la planificación de inventarios y el ERP necesitan obtener algunos datos sobre los materiales. Por lo tanto, algunos datos se replican en estos sistemas y, en el mejor de los casos, se mantienen sincronizados. Esta sincronización puede ser realizada manualmente por alguien o automáticamente sin interacción humana.
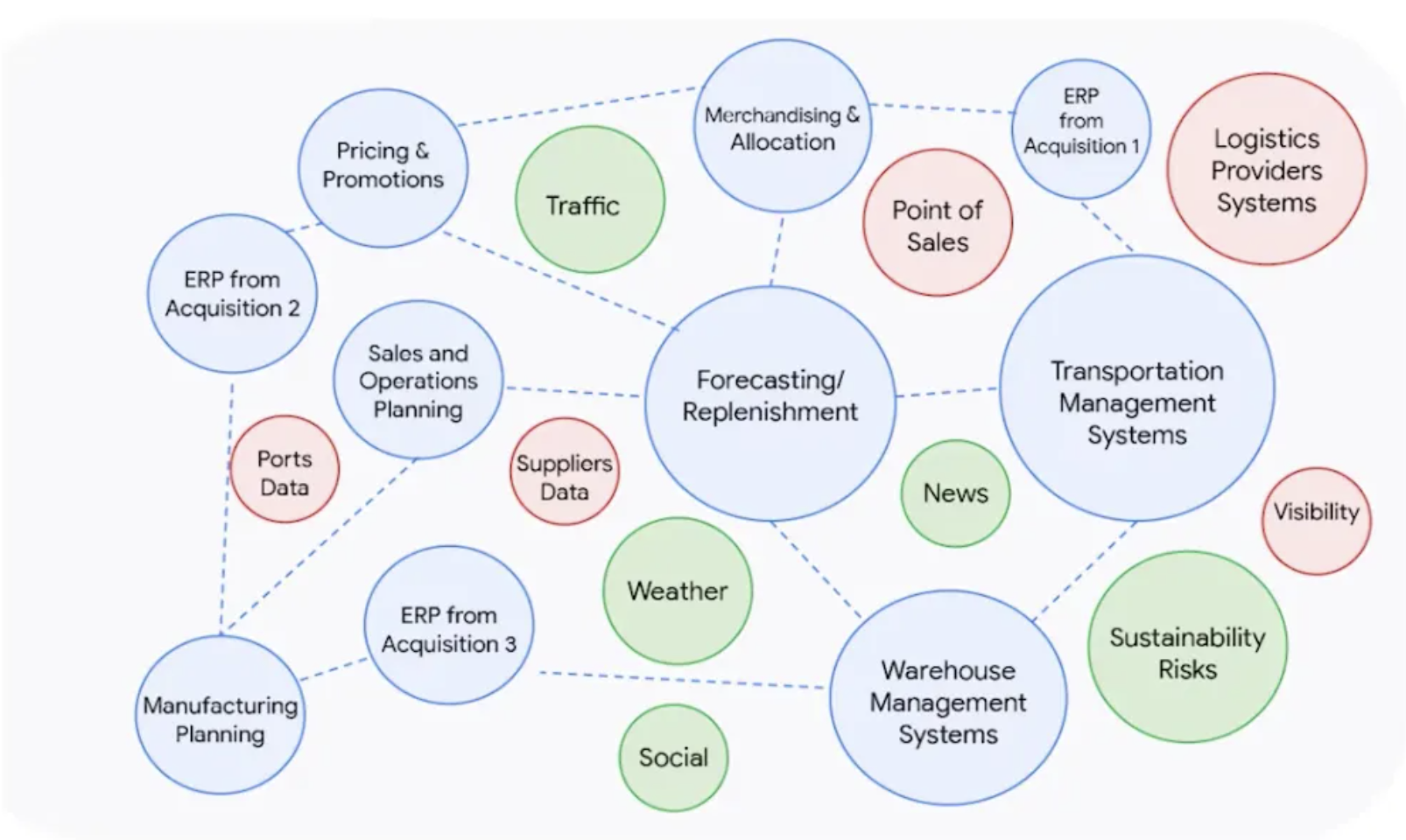
Fuente: Google for supply chain
Los métodos tradicionales no son suficientes para analizar el big data de la cadena de suministro
Los métodos tradicionales analizan los datos generados a lo largo de un periodo de tiempo o los datos de un acontecimiento concreto cuando éste ya ha ocurrido o el periodo de tiempo ha terminado. Teniendo en cuenta el volumen, la velocidad y la diversidad de los big data, estos métodos no son adecuados para crear ideas valiosas. Por eso, hoy en día los análisis se realizan en tiempo real y los resultados se presentan casi instantáneamente.
La mayoría de los responsables de la cadena de suministro o de la logística, incluso los que tienen una formación técnica, tienen poca o ninguna experiencia en este tipo de análisis de datos. Para extraer valor de los big data, las empresas deben adoptar tecnologías y métodos adecuados.
"Hoy en día, los análisis se realizan en tiempo real y los resultados se presentan casi instantáneamente."
En última instancia, la creación de valor a partir de los datos de la cadena de suministro comienza con la superación de estos tres obstáculos iniciales y se acelera con la aplicación de prácticas de agregación, interoperabilidad, automatización y análisis de datos.
Agregación, integración e interoperabilidad de datos
Los silos de datos en la cadena de suministro son un gran reto para la toma de decisiones basada en datos y un gran obstáculo para el crecimiento de las empresas. Saber exactamente qué son, cómo afectan a su equipo y a su empresa y cómo resolverlos puede ayudarle a superar este reto.
En la última década, los avances tecnológicos han permitido combinar distintos tipos de datos procedentes de diferentes fuentes y eliminar los bloqueos creados por los silos de datos. Hay tres conceptos importantes y de uso común que se suelen escuchar cuando se habla de romper los silos de datos.
La agregación de datos, que en el contexto de la cadena de suministro significa recopilar datos de la cadena de suministro de múltiples fuentes y ponerlos en grupos lógicos (conjuntos de datos) con fines de modelización.
La integración de los datos se refiere al proceso de recopilación de resultados de múltiples conjuntos de datos.
Por último, la interoperabilidad de los datos significa que un sistema es capaz de trabajar fácilmente con otros sistemas. En el contexto de la cadena de suministro, significa que los sistemas de cada socio comercial son capaces de comunicarse y entenderse entre sí y, por tanto, pueden trabajar juntos para hacer algo útil.
La agregación de datos, la integración y la interoperabilidad son más eficaces cuando se utilizan conjuntamente y en armonía. Estas tres prácticas ayudan a las empresas a obtener información de una versión sintética de sus datos. La calidad del análisis final de los datos depende de la exactitud e integridad de la agregación de datos.
Por lo tanto, las empresas que pretenden obtener información a partir de grandes cantidades de datos deben comprender cómo recopilarlos de forma eficaz mediante la agregación y analizarlos mediante la integración. Las empresas pueden aplicar estas prácticas tanto a los datos generados interna como externamente. Este último aspecto nos lleva al debate sobre el intercambio de datos e información entre empresas.
"La calidad del análisis de los datos depende de la precisión de su agregación."
¿Por qué es necesario agregar los datos internos?
Las empresas no siempre tienen un conocimiento completo de los datos generados internamente y, en consecuencia, no tienen una visión clara y completa de sus operaciones. Esto puede deberse a la falta de comunicación entre los distintos departamentos y equipos o a que los sistemas son diferentes porque no están interconectados. Como resultado, los datos no pueden pasar fácilmente de un departamento a otro de la organización. Esto sucede principalmente porque no hay herramientas adecuadas para realizar esta conexión vital y permitir un flujo continuo de información.
No es raro que un gestor de la cadena de suministro compruebe los detalles del inventario en el SGA de la empresa y pase al SGT para comprobar los detalles de la distribución y validar la economía en el ERP. La falta de flujo de datos en tiempo real y de sincronización entre estos sistemas puede provocar graves trastornos operativos y empresariales, como una planificación incorrecta (o poco óptima) del transporte, retrasos y reclamaciones de los clientes.
Por eso es importante hablar de agregación, integración e interoperabilidad de los datos generados internamente. Dependiendo del tamaño de la empresa, los datos pueden recogerse y agregarse de diferentes departamentos, centros de producción, almacenes, centros de distribución o tiendas dentro de la misma empresa. Este flujo de datos en tiempo real eliminará los silos en los sistemas de la empresa y sincronizará todos los datos, lo que permitirá a la empresa gestionar con éxito las operaciones de la cadena de suministro, reducir los errores y aumentar la eficiencia.
¿Cómo se agregan los datos externos?
Al hablar del flujo continuo de datos en tiempo real, las prácticas de agregación, integración e interoperabilidad de datos se relacionan directamente con el intercambio de información entre socios comerciales, proveedores y clientes. Las discrepancias en la información pueden tener un impacto negativo en las operaciones empresariales, en los esfuerzos de transparencia de la cadena de suministro y en las relaciones con los socios comerciales, además de obstaculizar los esfuerzos de cumplimiento de la normativa.
Transmisión manual
Tradicionalmente, las empresas transmiten los datos que quieren compartir con sus proveedores y clientes enviando la información por correo electrónico u hojas de Excel, o por teléfono. En la actualidad, estos métodos están perdiendo popularidad porque provocan pérdidas de información, confusión e ineficacia operativa.
Integración directa
A principios de la década de 2010, se produjo una interacción directa entre los sistemas. En estas aplicaciones, los sistemas informáticos se integraban directamente entre sí, lo que significa que las entradas de un sistema proporcionaban actualizaciones al otro. Esta automatización creó un intercambio de conocimientos oportuno y fluido entre las partes y resolvió los problemas causados por las actualizaciones manuales. Sin embargo, vincular los sistemas informáticos, sobre todo para integrar a todos los socios comerciales, no siempre es la solución óptima, ya que la variedad de partes y la cantidad de datos que intervienen en el proceso conllevan altos costes de integración y complicaciones.
Soluciones de agregación (EDI, API…)
Una solución creativa para la agregación de datos consiste en permitir que cada parte envíe elementos de datos predefinidos a una herramienta de agregación de datos, que a su vez actúa como depósito. Cuando se producen eventos, las partes implicadas transmiten sus actualizaciones a la herramienta de agregación: pueden acceder al repositorio y realizar sus propias consultas para responder a las preguntas y supervisar el progreso. Tanto las tecnologías de intercambio electrónico de datos (EDI) como las de interfaz de programación de aplicaciones (API) aplican esta lógica. La diferencia es que las transmisiones API suelen estar basadas en Internet o en la nube, proporcionan actualizaciones en tiempo real y pueden gestionar el intercambio de datos entre diferentes sistemas en cuestión de segundos, mientras que el EDI sólo establece una conexión entre dos sistemas EDI y el intercambio de datos lleva más tiempo⁶. Lo que el EDI tarda entre 30 minutos y 2 horas en cargar, la API lo hace en minutos.
"Las prácticas de agregación, integración e interoperabilidad de datos están directamente relacionadas con el intercambio de información entre socios comerciales, proveedores y clientes."
Tecnologías que permiten la automatización y el análisis de datos
Existen grandes oportunidades y un enorme potencial de optimización si una empresa es capaz de almacenar, agregar y combinar datos y luego utilizar los resultados para realizar análisis en profundidad. El principal problema para las empresas es cómo elegir la pila tecnológica y el enfoque adecuados para crear soluciones basadas en datos de forma eficiente.
Al contrario de lo que se cree, las soluciones de análisis avanzado, la Inteligencia Artificial y las tecnologías de Machine Learning no son sólo accesibles para las empresas tecnológicas o las grandes corporaciones. La extracción de información de los datos está mejorando, al igual que el software disponible para aplicar técnicas muy sofisticadas. Gracias a algunos agentes del mercado, estas tecnologías y soluciones se están convirtiendo en la columna vertebral de los procesos digitales.
Un ejemplo real de Machine Learning
Hay muchas técnicas y tecnologías esenciales para el análisis de datos, como las consultas SQL, el análisis de big data, la búsqueda de texto completo, el análisis en tiempo real y el aprendizaje automático o Machine Learning. Este último, por ejemplo, desarrolla algoritmos que permiten a los ordenadores evolucionar su comportamiento a partir de datos empíricos. De este modo, los algoritmos aprenden automáticamente a reconocer patrones complejos y a tomar decisiones inteligentes a partir de los datos.
Pensemos en las solicitudes comerciales que recibimos por e-mail. Si aplicamos algoritmos inteligentes y los entrenamos con un número suficiente de ejemplos, estos algoritmos serán capaces de identificar patrones y extraer información como el nombre del remitente, la información de contacto, la información del producto, etc. y comunicarla a nuestro sistema ERP. Todo esto ocurrirá automáticamente y en cuestión de segundos, sin ninguna interacción humana.
"Los algoritmos inteligentes aprenden automáticamente a reconocer patrones complejos y a tomar decisiones inteligentes a partir de los datos."
¿Cuáles son los beneficios reales del análisis de datos de la cadena de suministro?
an Sigmund comparte una cifra muy interesante en el libro Disrupting Logistics, proporcionando una visión general de dónde la toma de decisiones basada en datos a través del análisis de la cadena de suministro genera valor a lo largo de la cadena de suministro⁷.

Fuente: Disrupting Logistics (Future of Business and Finance)
Hoy en día, la figura muestra fundamentalmente la importancia de pensar estratégicamente en la cadena de suministro, ya que los productos, los clientes y los requisitos del mercado cambian constantemente. Según el autor, la enorme cantidad de datos recogidos a lo largo de la cadena ofrece a las empresas grandes oportunidades para optimizar el diseño de la red, las decisiones estratégicas de abastecimiento y los flujos de productos de forma continua.
Un informe publicado por el McKinsey Global Institute afirma que las oportunidades de análisis de la cadena de suministro pueden encontrarse en todas las etapas de la misma, como la planificación, la producción, el almacén, el transporte, el punto de venta y el consumidor⁸.
Por ejemplo, en el sector del transporte, las empresas ya utilizan las tecnologías GPS para reducir los tiempos de espera mediante la asignación de bahías de almacenamiento en tiempo real. También han empezado a aplicar tecnologías de optimización de rutas, seleccionando la mejor ruta para las entregas. Esto ayuda a reducir los viajes innecesarios y, en última instancia, a reducir los costes.
"Las oportunidades de análisis de la cadena de suministro pueden encontrarse en todas las etapas de la misma, como la planificación, la producción, el almacén, el transporte, el punto de venta y el consumidor."
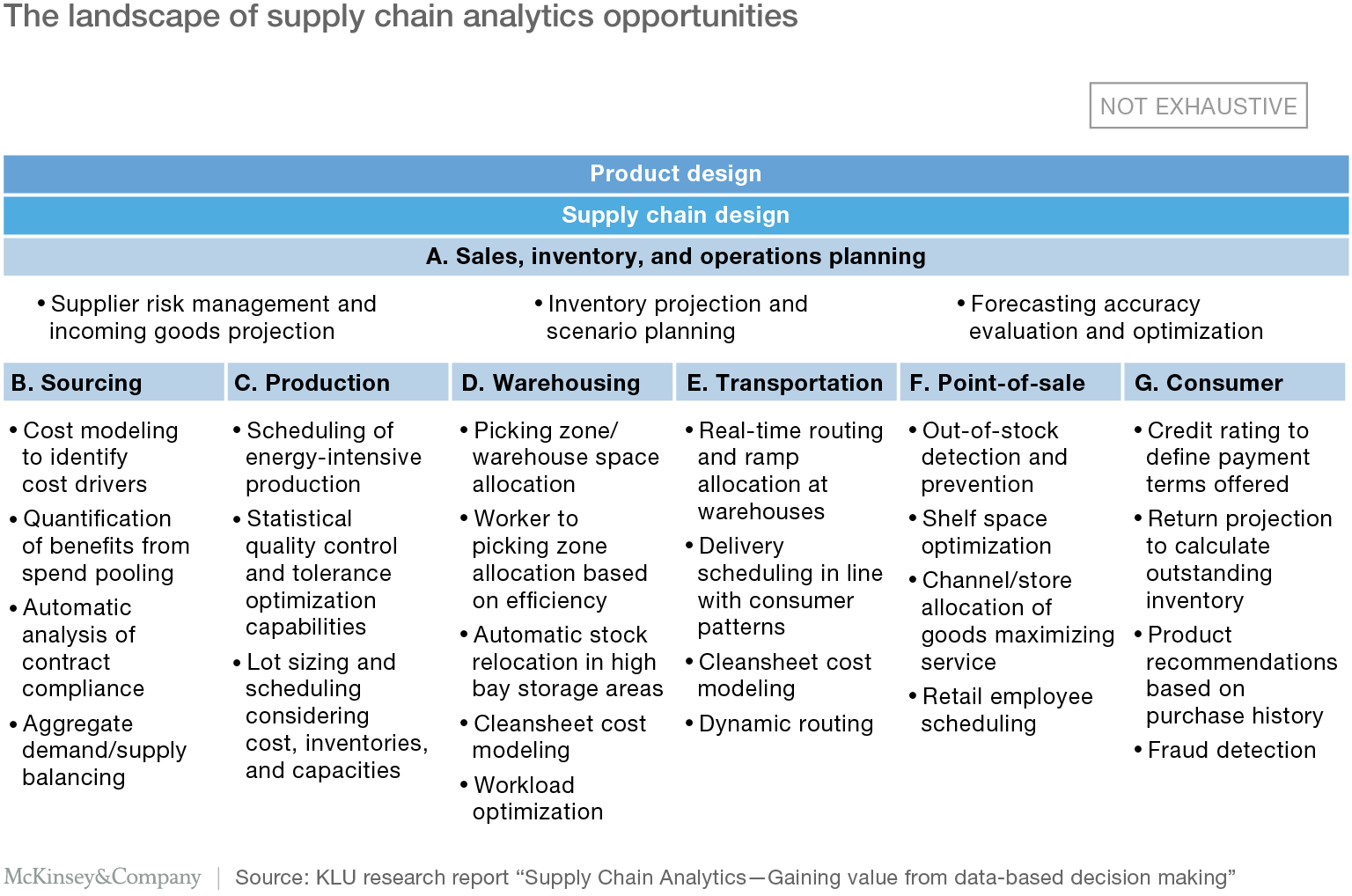
4 ormas de crear valor a partir del big data de la cadena de suministro
1. Crear transparencia
Facilitar el acceso de las partes interesadas a los datos relevantes puede romper los silos entre los distintos departamentos, reducir los tiempos de búsqueda y procesamiento y mejorar la calidad. La colaboración entre los socios de la cadena de suministro y el intercambio de datos pueden utilizarse para la elaboración de modelos predictivos y la toma de decisiones. Compartir información importante, dentro de la empresa, entre las distintas divisiones o externamente, con proveedores, clientes y socios, aumenta la transparencia de la cadena de suministro.
La transparencia impulsa la toma de decisiones, consolida las capacidades de decisión y las hace más eficientes. Por ejemplo, la total visibilidad y transparencia de los datos de la oferta y la demanda pueden orientar la planificación de los proveedores y las existencias. Esto puede influir positivamente en la planificación y ejecución de las operaciones logísticas. En la práctica, se crea un efecto dominó: si se facilita el proceso de toma de decisiones del departamento de aprovisionamiento, se mejorará y optimizará la carga de trabajo de los departamentos de almacén y logística.
Las empresas pueden crear un valor empresarial real a través del fuerte vínculo entre los datos de la cadena de suministro, la transparencia y la toma de decisiones eficiente.
2. Mejorar el rendimiento
La recopilación de datos de rendimiento más precisos y detallados permite a las empresas comprender las causas de determinados problemas y definir nuevas estrategias para mejorar el rendimiento. Esto puede aplicarse en varios casos, desde los inventarios de productos hasta la planificación de rutas. La planificación de rutas, por ejemplo, si se hace manualmente, puede ser un reto para la empresa. Esto se debe a que implica muchas limitaciones, como el tiempo, los recursos, el operador, las condiciones, la comunicación y la tecnología. Los métodos manuales o estáticos pueden provocar costosos errores humanos, falta de capacidad de respuesta y de reacción inmediata. Para eliminar estas limitaciones, se aprovechan los datos históricos y en tiempo real. Encontrar el mejor camino permite a las empresas ahorrar tiempo en paradas innecesarias e ineficaces, utilizar los recursos de forma eficiente, ahorrar tiempo y mejorar continuamente la eficiencia operativa.
Cuando hay que resolver un problema de rendimiento, es crucial conocer el problema exacto. Sólo el acceso a los datos pertinentes y el uso de las capacidades de análisis de datos pueden ayudar a identificar la raíz del problema. Además, esto hace que todas las partes interesadas vayan en la misma dirección, gestionando las expectativas y consiguiendo resultados.
3. Reducción de actividades que quitan tiempo
Los análisis avanzados pueden reducir las tareas manuales que requieren mucho tiempo y trabajo. Según Gartner, los trabajadores desperdician entre el 20% y el 30% de su semana laboral gestionando documentos o información basada en documentos⁹. El uso de algoritmos inteligentes y la automatización pueden optimizar los procesos empresariales y mejorar la precisión o los tiempos de respuesta.
La automatización de tareas que consumen mucho tiempo, desde el procesamiento de pedidos hasta el envío automático, puede mejorar la eficiencia, reducir los errores humanos, aumentar el rendimiento y la velocidad de la cadena de suministro y ahorrar tiempo y dinero a largo plazo.
La renovación de los procesos existentes con procesos automatizados no sustituye necesariamente el esfuerzo humano, pero ayuda a las empresas a racionalizar las operaciones y aumentar la productividad. De este modo, las empresas pueden asignar sus valiosos recursos a actividades más importantes e invertir más en el desarrollo de productos, el marketing y otras iniciativas cruciales.
4. Productos y servicios innovadores
El análisis de los datos de la cadena de suministro permite a las empresas crear nuevos productos y servicios, innovar los existentes y poner al día su negocio. Reunir las aportaciones internas y externas es fundamental para crear nuevos productos y lograr una gestión completa de los mismos. Sin el análisis, el desarrollo de productos se reduce a lo básico: desarrollar una idea de producto, ponerla en práctica en función del resultado final y no considerar si cumple o supera las expectativas del cliente.
El análisis de big data en la cadena de suministro simplifica el proceso de desarrollo de productos. Se centra en los datos correctos que hay que estudiar y reduce el tiempo empleado en considerables pruebas y errores, en su mayoría impulsados por los equipos de investigación y desarrollo.
Los fabricantes pueden utilizar los datos de los productos reales para mejorar el desarrollo de la próxima generación de productos y crear ofertas innovadoras de servicios posventa. Los minoristas pueden analizar los datos de los puntos de venta, el inventario y el volumen de producción para determinar qué productos poner a la venta y cuándo lanzar nuevas ofertas.
Conclusiones
Hoy en día, cada vez más personas, empresas, dispositivos, sensores y sistemas están conectados por redes digitales. La capacidad de generar, comunicar, compartir y acceder a los datos está fuertemente influenciada por esta tendencia. Ya hay más de 30 millones de dispositivos conectados en red en los sectores del transporte, la automoción, la industria, los servicios públicos y el comercio minorista. El número de estos dispositivos aumenta a un ritmo superior al 30% anual. En un futuro próximo, el big data y el análisis de datos de la cadena de suministro se convertirán en una ventaja competitiva clave para las empresas. Los primeros en adoptarlo ya han empezado a crear capacidades de análisis y automatización de datos.
Notas
1- OECD Glossary of Statistical Terms. OECD. 2008.
2- Disrupting Logistics (Future of Business and Finance) (p. 165), Springer International Publishing. Kindle Edition.
3- Ibidem.
4- Ivi, (p. 169).
5- Ibidem
6- Netsuite, Supply Chain Analytics: What It Is & Why It Matters
7- Disrupting Logistics (Future of Business and Finance), (p. 170).
8- MGI: Big data and the supply chain: The big-supply-chain analytics landscape (Part 1)
 Reglamento UE: la información electrónica del transporte de mercancías
Reglamento UE: la información electrónica del transporte de mercancías ¿Cómo gestionar los datos dispersos en diferentes plataformas?
¿Cómo gestionar los datos dispersos en diferentes plataformas? ¿Qué herramientas hay que usar para acceder rápidamente a los datos?
¿Qué herramientas hay que usar para acceder rápidamente a los datos? Comparte datos y conoce riesgos con una plataforma digital
Comparte datos y conoce riesgos con una plataforma digitalContactos
Domicilio social
Via S. Quasimodo 42
40013 Castel Maggiore (BO) – Italia
Sede Operativa
Via Bernardo Quaranta, 40
20139 Milano – Italia
Síguenos

